Insights23 min read
The Missing Layer: A Structural Gap in the AI Infrastructure Stack
by Jaepil Jeong | April 10, 2026
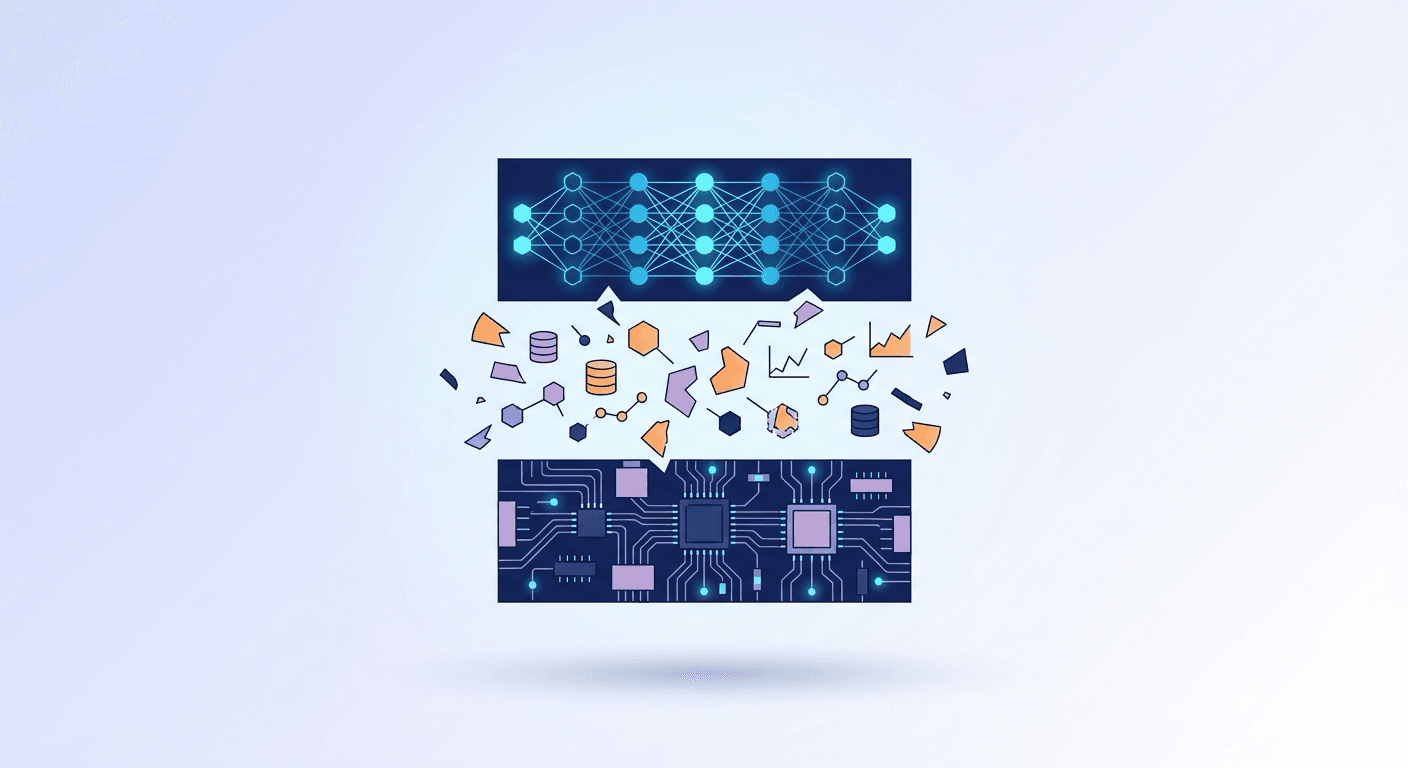
Between models and hardware lies an invisible structural gap — a data layer that should exist but doesn't. We examine why the current AI infrastructure stack is fragmented, why this is a structural problem rather than a transitional one, and what conditions a proper solution must satisfy. We then present UQA and the Cognica engine as one concrete response to these conditions.
Read Post